Google’s TurboQuant Compression May Support Faster Inference, Same Accuracy on Less Capable Hardware
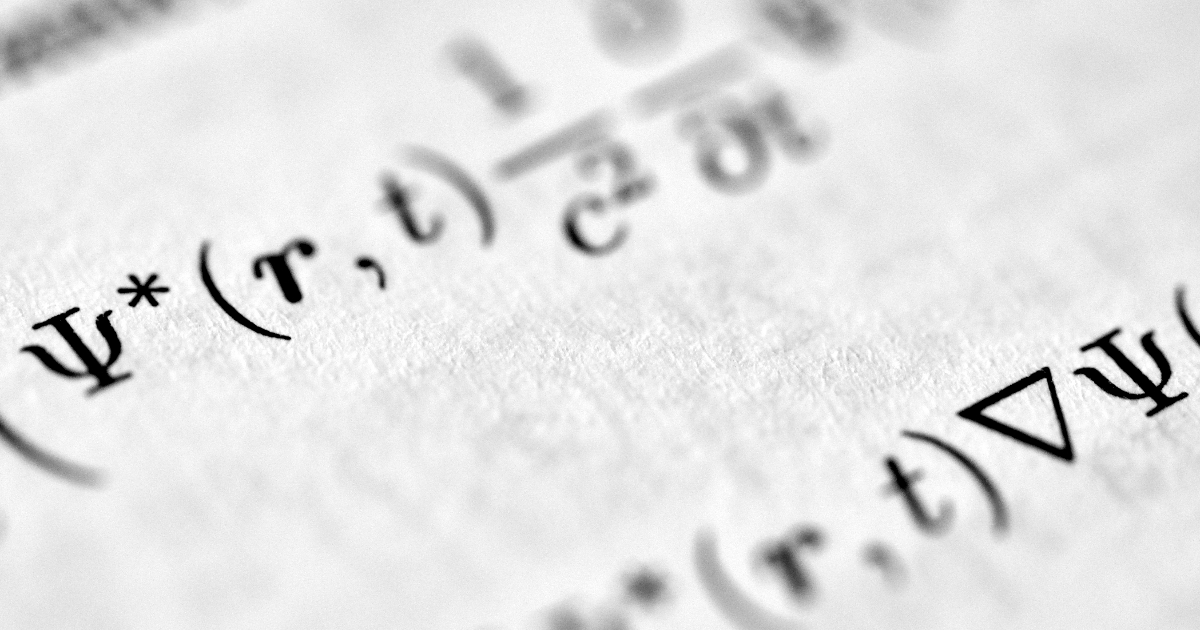
Posted on Wed Apr 15 2026 | 10:23 pm
Google Research unveiled TurboQuant, a novel quantization algorithm that compresses large language models’ Key-Value caches by up to 6x. With 3.5-bit compression, near-zero accuracy loss, and no retraining needed, it allows developers to run massive context windows on significantly more modest hardware than previously required. Early community benchmarks confirm significant efficiency gains.
Search
Categories
Side Widget
You can put anything you want inside of these side widgets. They are easy to use, and feature the new Bootstrap 4 card containers!